



While a generic LLM like OpenAI ChatGPT may have some familiarity with your domain, key information specific to your corporation, like internal documentation or emails, is not available to them by default. Therefore, such LLMs lack the necessary context for providing the best responses. It is possible to train general-purpose LLMs on your business-specific use cases. LLM developers overcome the limitations of generic models by steering them toward the most relevant outputs for your custom needs. They train large language models exclusively on your enterprise's data sets to generate tailored responses.
Types of LLM Training
LLM Fine-Tuning
Fine-tuning is the training of a general-purpose LLM that has already been pre-trained. Such an LLM has generic knowledge but does not perform well on domain-specific tasks without further training.
Fine-tuning feeds an LLM with domain-specific labeled examples to allow it to complete domain-specific tasks without errors and hallucinations. It's a customization of a general-purpose LLM with respect to the expertise area. Such an LLM can better recognize specific nuances, like legal jargon, medical terms or individual preferences of users.
Fine-tuning is often split into training, validation, and test sets.
The labeled dataset should be relevant to the specific task the LLM must learn to perform, be of high quality (without inconsistent data and duplicates), have sufficient quantity, and be in the form of inputs and outputs.
A pre-trained LLM usually consists of different layers (each one processes the input in its own way). For example, ChatGPT-4 has 120 layers. When fine-tuning such an LLM, layers representing general knowledge are kept unchanged, while only the top and later layers are modified according to the task-specific data.
The goal is to make the model’s predictions as close as possible to the desired output (the validation dataset is used to measure this). Both automated metrics (BLEU and ROUGE scores) and human evaluations are used to get a 360° view of a model's performance.
What do machine learning engineers do in the process of the LLM fine-tuning? They focus on finding:
- the optimal learning rate (the speed at which ML algorithms adjust some of their parameters automatically) to avoid too high or too low rates.
- the right batch size (the number of training examples of the algorithm processes before trying to improve the model). This mitigates overgeneralization (when it ignores exceptions or variations), and overfitting (when it memorizes without understanding the underlying principles).
- the right number of epochs (training iterations) to ensure the model does not train for so long that it begins to overfit.
They also use regularization techniques to discourage the model from giving too much importance to one or a few features (characteristics) of the data, and to encourage the consideration of all features more evenly to improve performance on new, unseen data.
Retrieval-Augmented Training of Large Language Models
Fine-tuned LLMs may become outdated if there is a lot of dynamic data in the domain, as they are tied to the facts in their initial training datasets. They cannot acquire new information and thus may respond inaccurately. Fine-tuning requires a lot of labeled data, and in general, the overall cost of fine-tuning may be relatively higher compared to Retrieval-Augmented Generation (RAG).
RAG is an approach that improves existing language models by integrating retrieval capabilities directly into the generation process.
From a user perspective, RAG may be referred to as a search engine with a built-in content writer. RAG architecture is used to increase the performance of an LLM by merging the standard generative capabilities with retrieval mechanisms. It works as follows: searching vast external knowledge bases, finding relevant information for a given prompt, and generating new text based on this information.
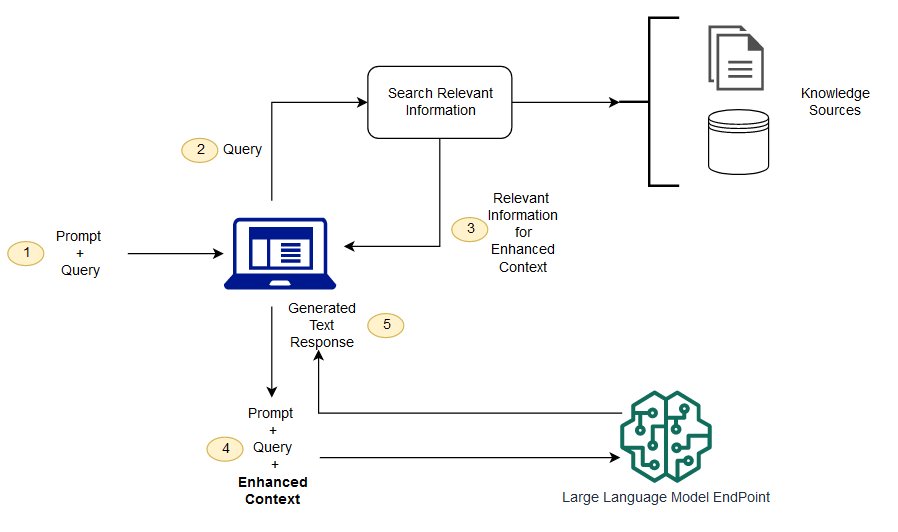
Machine learning engineers often implement RAG by relying on a vector database. The knowledge base is converted into vectors to be stored in this database. When a user submits a query to the LMM, it’s also converted into a vector. The retrieval component searches the vector database for similar vectors. The most similar information is combined with the user query. This forms the augmented query that is ready to be fed into an LLM to let it generate an up-to-date response.
RAG prevents the problem of 'best-guess' assumptions and generates factually correct and unbiased responses because it adapts to situations where the information has changed over time. Since it generates information from the retrieved data, it becomes nearly impossible for it to produce fabricated responses. The source of an LLM’s answer can easily be identified based on the references, which are essential for quality assurance.
Chatbots with RAG capabilities efficiently retrieve relevant information from an organization's instruction manuals and technical documents (for customer support), up-to-date medical documents and clinical guidelines (for medics), from an institution's study materials according to specific curriculum requirements (for educational institutions), and from a repository of former depositions and legal decisions (for legal professionals). RAG also improves language translation in specialized fields.
LLM Training Stages
Data Sources Preparation
The goal here is to find and prepare data that is sufficient in volume, relevant and focused directly on the target use cases, and relatively high in quality (ready to clean).
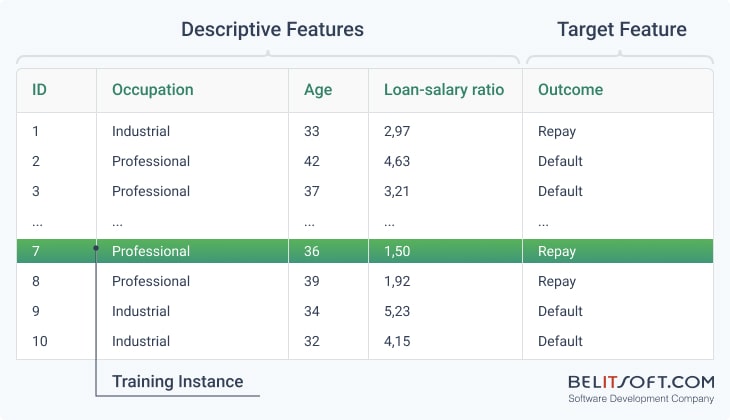
Example of a labeled dataset with descriptive features and a target feature
Data Cleaning
At this stage, machine learning engineers remove corrupted data from training data sets, reduce duplicate copies of the same data to a single one, and complete (when feasible) incomplete data by adding missing information. OpenRefine and a variety of proprietary data quality and cleaning tools are available for this purpose.
Data Formatting
Models recognize patterns and input-output relationships better if the training data is structured based on specified guidelines. Examples of inputs are customer questions, and outputs are the support team's responses. Machine learning engineers may reformat the source data using JSON. They use custom scripts to expedite the process and manually tweak and clean up where it’s necessary.
Adjusting Parameters
Transformer-based deep learning frameworks are used to train models, and parameters are customized for these models.
Tweaking parameters of how the LLM interprets data is a way to guide it toward behaving in desired ways. The AI team knows exactly which parameters to customize and which ones not to, using methods like LoRA, as well as the best way to customize them. They adjust model weights to indicate the relationship strength between data within a training set.
LLM Training Process
Machine learning engineers run code that learns from the custom data using previously set parameters. The process may be finished after either hours or weeks, depending on the size of the data.
They train the LLM in a three-stage process that includes self-supervised learning, supervised learning, and reinforcement learning.
First, the model reads a lot of text in your domain on its own. It learns how language works and starts to guess what words/sentences might come next.
Then, the model is given examples by our data scientists to learn from. After this, it can follow instructions and do well on new tasks it hasn't seen before.
Finally, the model's answers are graded by our staff to teach the model which answers are preferred.
Then the trained model is tested. The goal is to have an LLM that is accurate across your domain, consistent, uses natural language, performs well in real-world tasks like problem-solving, and answers factual questions without hallucinations.
In the end, the LLM is being integrated with the appropriate real-life application.

Rate this article
Our Clients' Feedback












They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.

СEO at ElearningForce International (United States/Denmark)
Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.
Global Head of Commercial Development L&D at Technicolor